node 基础
首先要理解服务器开发是什么?简单的说就是通过一门语音,操作处理各种文件——增删改查。
例如 Java 、Python 等可以作为全栈的高级语言,就是因为其满足服务器开发要求。前端如今的工厂化,实际上都源于 Node,在本地运行一个服务,持续运行编辑中的代码。这是本质,而浏览器呢?如 V8 引擎实际上只是做了 js 代码的解析工作。
Node 是什么?
Node.js 是一个基于 V8 JavaScript 引擎的 JavaScrip t 运行时环境。简单理解,就是 Node 是基于 V8 引擎的能够在本地运行 JavaScript 代码的环境。当然由于 Chrome 浏览器内部还需要解析、渲染 HTML 和 CSS 等相关渲染引擎,另外还需要提供支持浏览器操作的 API、浏览器自己的事件循环等,这部分做了取舍。但是同时由于要处理本地文件,所以 Node 自身也添加了一些额外的 API 如文件系统读/写、网络 IO、加密、压缩解压文件等。
体系架构
Node.js 主要分为四大部分,Node Standard Library,Node Bindings,V8,Libuv,架构图如下:
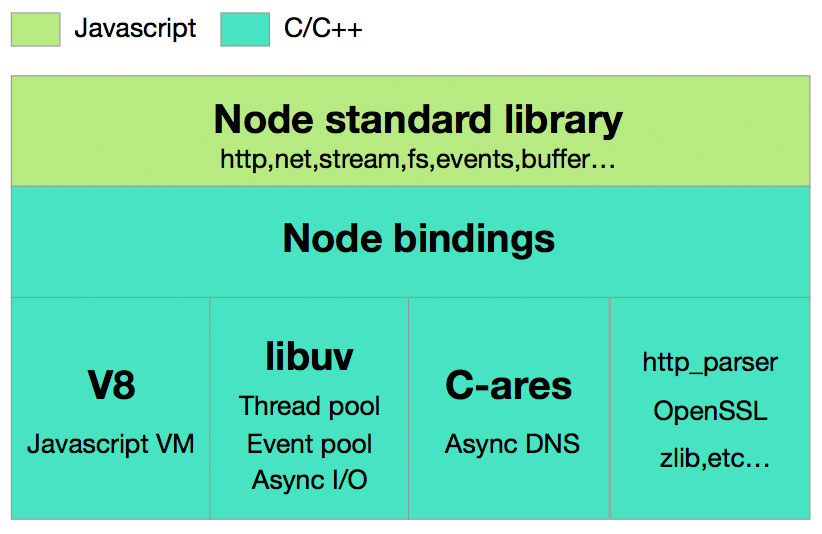
- Node Standard Library 是我们每天都在用的标准库,如 Http, Buffer 模块。
- Node Bindings 是沟通 JS 和 C++的桥梁,封装 V8 和 Libuv 的细节,向上层提供基础 API 服务。
- 这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。
- V8 是 Google 开发的 JavaScript 引擎,提供 JavaScript 运行环境,可以说它就是 Node.js 的发动机。
- Libuv 是专门为 Node.js 开发的一个封装库,提供跨平台的异步 I/O 能力.
- C-ares:提供了异步处理 DNS 相关的能力。
- http_parser、OpenSSL、zlib 等:提供包括 http 解析、SSL、数据压缩等其他的能力。
文件系统 File System
文件系统是服务器开发的基础,服务器必须支持数据的交互操作。对于任何一个为服务器端服务的语言或者框架通常都会有自己的文件系统。Node 的文件系统模块是 fs 。
CommonJS 导入模块
CommonJS 是一种模块规范,用于在 JavaScript 环境中定义模块的创建、导出和引入方式。它是 Node.js 中使用的默认模块系统,并且也被广泛地应用于其他 JavaScript 环境中。
在 CommonJS 规范下,每个模块都是一个独立的文件,可以通过 require 函数来导入其他模块,并通过 module.exports 或 exports 对象来导出自己的公共部分。例如:
// moduleA.js
const add = (a, b) => a + b
module.exports = { add }
// moduleB.js
const { add } = require('./moduleA')
console.log(add(1, 2)) // 输出 3
在上面的例子中,moduleA.js 中导出了一个名为 add 的函数,并将其赋值给 module.exports 对象。然后,在 moduleB.js 中,我们通过 require 函数引入了 moduleA.js 文件,并使用解构赋值语法来获取 moduleA.js 导出的 add 函数,然后调用了它。
需要注意的是,在 CommonJS 规范下,模块是同步加载的,这意味着当一个模块被加载时,它的所有依赖项也会被加载并执行。这可能会影响应用程序的性能,特别是当应用程序变得越来越大时。因此,随着 ECMAScript 2015 规范的推出,JavaScript 社区开始使用 ES6 模块系统来代替 CommonJS。
require 和 import 都是用于在 JavaScript 中导入模块的关键字,但它们有以下区别:
- 语法:
require是 CommonJS 规范定义的模块导入方式,而import是 ES6 模块化规范定义的模块导入方式。两者的语法和使用方法略有不同。
javascript复制代码// CommonJS 导入方式
const moduleA = require('./moduleA')
// ES6 模块导入方式
import moduleA from './moduleA'
- 动态导入:使用
require导入的模块是在运行时动态加载的,可以在函数内部或其他条件下进行导入(实质是通过最后的 Webpack 进行打包编译处理);而使用import导入的模块是在编译时静态加载的,不能在函数内部或其他条件下进行导入。
// CommonJS 动态导入方式
function loadModule(filename) {
return require('./' + filename)
}
// ES6 模块静态导入方式
const filename = 'moduleA.js'
import(`./${filename}`).then((module) => {
// 执行操作
})
- 默认导出:在 CommonJS 规范中,使用
module.exports或exports对象来导出模块的公共部分;而在 ES6 模块系统中,则默认导出一个模块,可以通过export default语句来指定默认导出。
// CommonJS 导出方式
module.exports = { add } // 或者 exports.add = add
// ES6 模块默认导出
export default { add }
需要注意的是,虽然 import 和 export 是 ES6 模块化规范中定义的关键字,但它们在许多现代浏览器和 Node.js 环境中已经得到了支持。但在一些旧的浏览器或 Node.js 版本中,可能需要使用打包工具(如 webpack、Browserify 等)来转换成 CommonJS 规范的代码。
读取文件的三种方式
fs 上有几个文件读取的 API 常用的有俩个:fs.readFileSync(同步读取)和 fs.readFile(异步读取,俩种方式)。
同步读取
// 同步读取,获取返回值进行同步操作 const fs = require('fs') const res = fs.readFileSync('./text.txt', { encoding: 'utf8', }) console.log(res)异步读取: 回调函数
// fs.readFile 第二个参数是回调函数 const fs = require('fs') fs.readFile( './text.txt', { encoding: 'utf8', }, (err, data) => { if (err) { console.log('读取文件错误:', err) return } console.log('读取文件结果:', data) } )异步读取:Promise
// 通过链式调用的 Promise 操作 const fs = require('fs') fs.promises .readFile('./text.txt', { encoding: 'utf-8', }) .then((res) => { console.log('获取到结果:', res) }) .catch((err) => { console.log('发生了错误:', err) })
文件描述符的使用
在操作系统中,文件描述符(File Descriptor)是一个非负整数,用于标识打开的文件、网络连接或其他 I/O 设备。在 Node.js 中,文件描述符通常使用整数来表示,并用于执行底层的 I/O 操作。
在常见的操作系统上,对于每个进程,内核都维护着一张当前打开着的文件和资源的表格。每个打开的文件都分配了一个称为文件描述符的简单的数字标识符。在系统层,所有文件系统操作都使用这些文件描述符来标识和跟踪每个特定的文件。(Windows 系统略有不同,但机制相同)
为了简化用户的工作,Node.js 抽象出操作系统之间的特定差异,并为所有打开的文件分配一个数字型的文件描述符。
当打开一个文件时,操作系统会为该文件分配一个唯一的文件描述符。可以使用这个文件描述符来读取、写入或关闭文件。在 Node.js 中,可以使用 fs.open 函数来打开一个文件,并获取该文件的文件描述符。例如:
const fs = require('fs')
// 打开文件,并获取文件描述符
fs.open('file.txt', 'r', (err, fd) => {
if (err) throw err
console.log(fd) // 打印文件描述符
// 或使用文件描述符进行 I/O 操作
// ...
// 关闭文件
fs.close(fd, (err) => {
if (err) throw err
})
})
在上面的例子中,我们使用 fs.open 函数打开了一个名为 file.txt 的文件,并获取了该文件的文件描述符 fd。接下来,我们可以使用 fd 来执行文件的 I/O 操作。最后,我们使用 fs.close 函数来关闭文件,释放文件描述符。
需要注意的是,文件描述符不仅被用于对文件的读写操作,还可以用于对套接字、管道等其他类型的文件进行 I/O 操作。
文件写入
在 Node.js 中,可以使用 fs.writeFile 或 fs.createWriteStream 函数来写入文件。
先看 fs.writeFile 函数:
fs.writeFile(file, data[, options], callback)
其中:
file:要写入的文件名或文件描述符。data:要写入的数据。options:一个可选的对象,用于指定写入选项,例如编码、文件模式、标志等。默认值为{ encoding: 'utf8', mode: 0o666, flag: 'w' }。encoding:字符编码形式,如果不填写encoding,返回的结果是Buffer(后续会介绍)。flag:读写模式,以下是几个常用的flag标志:'r':以只读模式打开文件。如果文件不存在,则会发生错误。'r+':以读写模式打开文件。如果文件不存在,则会发生错误。'w':以只写模式打开文件。如果文件不存在,则创建文件;如果存在,则清空文件内容。'w+':以读写模式打开文件。如果文件不存在,则创建文件;如果文件已经存在,则清空文件内容。'a':以追加模式打开文件。如果文件不存在,则创建文件。'a+':以读取和追加模式打开文件。如果文件不存在,则创建文件。
callback:当写入操作完成或出错时,回调函数将被调用。如果写入成功,则回调函数不会接收任何参数;如果出错,则回调函数将接收一个错误对象作为参数。
例如,以下代码在写入文件时使用了 encoding 和 flag 选项:
const fs = require('fs')
fs.writeFile(
'file.txt',
'Hello, world!',
{ encoding: 'utf8', flag: 'a+' },
(err) => {
if (err) throw err
console.log('Data written to file')
}
)
在上面的例子中,我们将字符串 'Hello, world!' 写入名为 file.txt 的文件中,并使用了 encoding 选项设置编码格式为 utf8,并使用了 flag 选项设置标志为 'a+'(追加写入)。
文件夹操作
除了基础的文件操作外,还需要对文件夹进行管理,常用的文件夹操作包括:创建、读取、删除、重命名等。
创建文件夹
可以使用
fs.mkdir函数来创建一个新的文件夹。该函数接受两个参数:要创建的文件夹路径以及一个回调函数。当创建操作完成或出错时,回调函数将被调用。例如:const fs = require('fs') fs.mkdir('newDir', (err) => { if (err) throw err console.log('Folder created') })在上面的例子中,我们使用
fs.mkdir函数创建了一个名为newDir的文件夹。如果创建失败,则会抛出错误;否则,将输出'Folder created'。读取文件夹
可以使用
fs.readdir函数来读取一个文件夹中的所有文件和子文件夹。该函数接受两个参数:要读取的文件夹路径以及一个回调函数。当读取操作完成或出错时,回调函数将被调用。例如:const fs = require('fs') fs.readdir('myDir', (err, files) => { if (err) throw err console.log(files) })在上面的例子中,我们使用
fs.readdir函数读取了名为myDir的文件夹中的所有文件和子文件夹,并将结果作为数组打印到控制台上。如果读取失败,则会抛出错误;否则,将输出文件和子文件夹的列表。需要注意的是,
fs.readdir函数只会返回文件夹中的文件和子文件夹的名称,而不会返回它们的内容。如果需要读取一个文件夹中的文件内容,需要分别打开每个文件并读取其内容。递归读取文件夹中所有的文件:
const fs = require('fs') function readDirectory(path) { fs.readdir(path, { withFileTypes: true }, (err, files) => { files.forEach((item) => { if (item.isDirectory()) { readDirectory(`${path}/${item.name}`) } else { console.log('获取到文件:', item.name) } }) }) } readDirectory('./myDir')删除文件夹
可以使用
fs.rmdir函数来删除一个文件夹。该函数接受两个参数:要删除的文件夹路径以及一个回调函数。当删除操作完成或出错时,回调函数将被调用。例如:const fs = require('fs') fs.rmdir('oldDir', (err) => { if (err) throw err console.log('Folder deleted') })在上面的例子中,我们使用
fs.rmdir函数删除了名为oldDir的文件夹。如果删除失败,则会抛出错误;否则,将输出'Folder deleted'。需要注意的是,在 Node.js 的文件系统模块中,
fs.unlink函数用于删除一个文件,而fs.rmdir函数用于删除一个文件夹。这两个函数默认情况下不会递归删除。如果要删除一个文件夹及其子文件夹和文件,可以使用第三方库
rimraf或del,它们提供了递归删除文件夹的功能。例如,使用
rimraf库来删除一个文件夹及其所有子文件夹和文件的示例代码如下:const rimraf = require('rimraf') rimraf('myDir', (err) => { if (err) throw err console.log('Folder deleted') })在上面的例子中,我们使用
rimraf函数删除了名为myDir的文件夹及其所有子文件夹和文件。如果删除失败,则会抛出错误;否则,将输出'Folder deleted'。此外,在执行删除操作时,请务必小心谨慎,确保不会意外删除或修改不想修改的文件或文件夹,特别是在使用递归删除的情况下。
重命名文件夹
可以使用
fs.rename函数来重命名一个文件夹。该函数接受三个参数:旧的文件夹路径、新的文件夹路径以及一个回调函数。当重命名操作完成或出错时,回调函数将被调用。例如:const fs = require('fs') // 对文件夹进行重命名 // 需要加路径 fs.rename('./oldDir', './newDir', (err) => { if (err) throw err console.log('Folder renamed') }) // 对文件进行重命名 // 重命名文件需要加后缀名! fs.rename('./oldFile.txt', './newFile.txt', (err) => { if (err) throw err console.log('File renamed') })在上面的例子中,我们使用
fs.rename函数将名为oldDir的文件夹重命名为newDir。如果重命名失败,则会抛出错误;否则,将输出'Folder renamed'。
需要注意的是,在执行文件夹操作时,请务必小心谨慎,确保不会意外删除或修改不想修改的文件夹。
Events 模块
Node.js 中的 events 模块提供了一个简单的事件驱动框架,可以方便地实现事件的监听和触发。可以使用 events 模块来创建自定义事件,并为这些事件注册回调函数。这个和 Vue 中的事件总线非常类似,而实际上 Vue 的事件总线就是基于此实现的。
以下是一个简单的示例,演示如何使用 events 模块来创建并触发一个自定义事件:
const EventEmitter = require('events')
class MyEmitter extends EventEmitter {}
// 创建 EventEmitter 实例
const myEmitter = new MyEmitter()
// 回调事件
function handleFn() {
console.log('Hello, world!')
}
// 监听事件
myEmitter.on('hello', handleFn)
// 发射事件
myEmitter.emit('hello') // 打印 'Hello, world!'
// 取消事件监听
myEmitter.off('hello', handleFn)
myEmitter.emit('hello') // 不再打印
在上面的例子中,我们首先创建了一个名为 MyEmitter 的自定义事件类,该类继承自 EventEmitter 类。然后我们创建了一个 myEmitter 实例,并为其注册了一个名为 'hello' 的事件及其回调函数,当该事件被触发时,将输出 'Hello, world!'。而后取消事件监听,再发送事件时,不再输出。
此外,也可以传递参数给事件回调函数,例如:
myEmitter.on('count', (count) => {
console.log(`Count: ${count}`)
})
myEmitter.emit('count', 42)
在上面的例子中,我们定义了一个名为 'count' 的事件,并将回调函数作为第二个参数传递给 on 方法。当该事件被触发时,它会将参数 42 传递给回调函数,并输出 'Count: 42'。
除了 on 和 emit 方法,EventEmitter 类还提供了其他方法,例如:
once:注册一个一次性事件,只在第一次触发时调用回调函数。prependListener: 将事件监听添加到最前面。removeListener:从指定事件的监听器数组中删除一个监听器。removeAllListeners:从所有事件的监听器数组中删除所有监听器。不传递参数的情况下, 移除所有事件名称的所有事件监听,在传递参数的情况下, 只会移除传递的事件名称的事件监听。
Buffer 类
计算机中所有的内容:文字、数字、图片、音频、视频最终都会使用二进制来表示。 JavaScript 可以直接去处理非常直观的数据:比如字符串,我们通常展示给用户的也是这些内容。但是服务器不同,服务器中药处理的更多的是服务器中的本地文件,像音视频等,这些都是由其它编码的二进制数据。
但是,二进制并不好直接操作,它较为抽象。Node 为开发者提供了一个全局类 Buffer。可以将 Buffer 看成一个存储二进制的数据,数组中的每一项,都可以保存 8 位二进制:0000 0000。
创建 Buffer
在 Node.js v6.x 版本中,Buffer 构造函数可以使用 new Buffer() 的方式进行调用。但是,在 Node.js v6.x 之后的版本中,new Buffer()这种方式已经被弃用,并且会抛出一个警告。
这是因为,new Buffer() 在创建一个新的 Buffer 实例时,默认情况下会将其内容初始化为零。然而,由于这种行为很容易导致安全漏洞和内存泄漏等问题,因此 Node.js 团队决定弃用这种方式,并引入了 Buffer.from() 和 Buffer.alloc() 方法来取代它。
如果在旧版本的 Node.js 中使用了 new Buffer(),那么可能需要修改代码以避免在更新到新版本的 Node.js 后出现异常或警告。如果要创建一个特定大小的 Buffer,请使用 Buffer.alloc() 方法(alloc 是分配的意思)。如果要通过字符串或字节数组等数据创建一个 Buffer,请使用 Buffer.from() 方法。
例如,以下代码演示了如何使用 Buffer.from() 方法创建并操作一个 Buffer:
const buf = Buffer.from('hello', 'utf8')
console.log(buf) // <Buffer 68 65 6c 6c 6f>
console.log(buf.toString('utf8')) // hello
console.log(buf[0]) // 104
buf[1] = 111
console.log(buf.toString('utf8')) // hollo
在上面的例子中,我们使用 Buffer.from 函数创建了一个包含字符串 'hello' 的 Buffer。我们还使用 console.log 和 toString 方法打印了该 Buffer 的内容和转换为字符串后的内容。我们还通过访问 buf 数组索引来修改了 Buffer 中的一个字节,并输出了修改后的结果。
Buffer.alloc(size[, fill[, encoding]]) 是 Node.js 中 Buffer 模块提供的一个用于创建新 Buffer 实例的方法。
该方法接受三个可选参数:
size:要创建的 Buffer 的大小,以字节为单位。fill:可选参数,用于填充 Buffer 的初始值。如果未提供,则默认为零。encoding:可选参数,指定fill参数的编码格式,默认为'utf8'。
Buffer.alloc() 方法会创建一个指定大小的新的 Buffer,并将其所有字节初始化为零或给定的 fill 值。这种方式可以确保创建的 Buffer 在使用前已经被初始化,从而避免了使用未初始化内存的潜在问题。
例如,以下代码演示了如何使用 Buffer.alloc() 方法创建并操作一个 Buffer:
const buf = Buffer.alloc(5)
console.log(buf) // <Buffer 00 00 00 00 00>
buf[1] = 0x61
console.log(buf) // <Buffer 00 61 00 00 00>
在上面的例子中,我们使用 Buffer.alloc() 方法创建了一个包含五个字节的新的 Buffer,并将其所有字节初始化为零。我们还通过访问 buf 数组索引来修改了 Buffer 中的一个字节,并输出了修改后的结果。
Buffer 的创建过程
在 Node.js 中,Buffer 是使用 C++ 底层库进行实现的。具体地说,Buffer 会在内存中分配一段连续的空间,用于存储二进制数据。
创建一个新的 Buffer 实例时,Node.js 会为其在内存中分配一段连续的空间,并将其所有字节初始化为零。如果指定了初始值,则会将其写入到这段连续的空间中。例如:
码const buf = Buffer.from('hello', 'utf8')
在上面的代码中,我们使用 Buffer.from() 方法创建了一个包含字符串 'hello' 的新的 Buffer 实例。当执行该行代码时,Node.js 会为该 Buffer 在内存中分配一段连续的空间,并将其所有字节初始化为 'hello' 字符串的 UTF-8 编码值。
需要注意的是,Node.js 并不会频繁地向操作系统申请内存空间。相反,它使用了一种称为 "slab allocation" 的机制来管理内存。
在 slab allocation 机制中,Node.js 会预先分配一些内存块(称为 "slab"),并将其缓存在内部的内存池中。当需要创建新的 Buffer 实例时,Node.js 会优先从该内存池中分配或复用已有的 slab,而不是向操作系统申请新的内存空间。这样可以避免频繁的内存分配和释放操作,提高了性能和效率。
另外,在 Node.js 中,Buffer 对象本身是一个 JavaScript 对象,它包装了底层的 C++ Buffer 对象。因此,当创建一个新的 Buffer 实例时,实际上是在 JavaScript 层面上创建了一个对象,而不是直接向操作系统申请内存空间。这个对象会引用底层的 C++ Buffer 对象,使得 JavaScript 层面可以方便地对二进制数据进行操作。由于这种间接的封装方式,也可以减少频繁向操作系统申请内存的开销。
需要注意的是,在极端情况下,如果创建了许多大型的 Buffer 实例,并且持有它们的引用,可能会导致内存泄漏等问题。因此,在使用 Buffer 时,建议注意内存的使用情况,并及时释放不再需要的对象。
OneMoreThing: 浏览器与 Node 的事件循环区别
前置知识:进程和线程的区别?
进程是 CPU 资源分配的最小单位,线程是 CPU 调度的最小单位。俩者的区别就好比工厂和工厂里的流水线。一个工厂里允许有多条流水线,而一条流水线一个项目只能做一种零部件。
JS 单线程的意思就是运行的工厂里只有一条流水线,所以任务得一个一个来,不能同时进行。
多线程就是多条流水线同时进行。(想象特斯拉工厂在多条流水线的转态下一个星期造一辆车)
浏览器中的 Event Loop:
宏任务(Macro-Task)和微任务(Micro-Task):
宏任务:setTimeOut、setInterval、setImmediate、script(整体代码)、I/O 操作和 UI 渲染等。
其中 setImmediate 是一个异步编程函数,执行优先程度更高,可以更快的响应。该方法用来把一些需要长时间运行的操作放在一个回调函数里,在浏览器完成后面的其他语句后,就立刻执行这个回调函数。值得注意的是,该方法并不标准,仅在 Node.js 和 Edge12 后实现。因此更多的在 Node 中讨论。
微任务:
new Promise().then(回调)、process.nextTick、MutationObserver(html5 新特性)等。process.nextTick这个微任务较为特殊,在 Node 中进行介绍,在 Node11 后,它会优先于其它微任务先执行。实际执行顺序:队列结构,先进先出。宏任务中包裹微任务,依次执行。
console.log('Global1') // 1 Promise.resolve().then(() => { console.log('Promise1') // 4 setTimeout(() => { console.log('setTimeout2') // 7 }, 0) }) console.log('Global2') // 2 setTimeout(() => { console.log('setTimeout1') // 5 Promise.resolve().then(() => { console.log('Promise2') // 6 }) }, 0) console.log('Global3') // 3- 上述代码,首先执行
script中的全体宏任务,所以依次打印 “Global1、Global2、Global3”。这其中会插入 1 个微任务Promise.resolve().then()和一个新的宏任务setTimeout。 - 执行微任务,打印“
Promise1”,而后再插入一个宏任务setTimeout。微任务执行结束,开始轮询新的宏任务。 - 此时有俩个宏任务,依次执行,打印“
setTimeout1”,再插入一个微任务Promise.resolve().then()。 - 有微任务,先执行队列中的微任务。打印“
Promise2”。结束当前宏任务。 - 执行剩下的宏任务,打印“
Promise2”。
因此最终的执行顺序是:“Global1、Global2、Global3、Promise1、setTimeout1、Promise2、setTimeout2”。
一句话总结,宏任务依次执行,当每一个宏任务中存在微任务,则先执行微任务队列中的所有任务。待宏任务中没有微任务了,则继续执行剩下的宏任务。
- 上述代码,首先执行
Node 中的 Event Loop:
Node.js 的运行机制如下:
- V8 引擎解析 JavaScript 脚本。
- 解析后的代码,调用 Node API。
- libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
- V8 引擎再将结果返回给用户。
libuv 引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
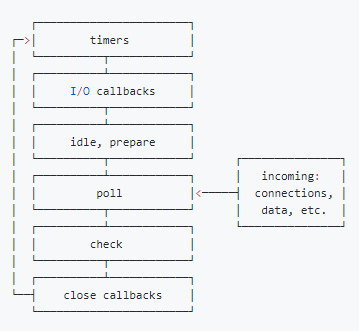
执行顺序为: incoming 外部输入数据 --> 轮询阶段(poll) --> 检查阶段(check) --> 关闭事件回调阶段(close callback) --> 定时器检测阶段(timer) --> I/O 事件回调阶段(I/O callbacks) --> 闲置阶段(idle, prepare) --> 新的轮询阶段(new poll)
- timers 阶段:这个阶段执行 timer(setTimeout、setInterval)的回调
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调
- idle, prepare 阶段:仅 node 内部使用
- poll 阶段:获取新的 I/O 事件, 适当的条件下 node 将阻塞在这里
- check 阶段:执行
setImmediate()的回调 - close callbacks 阶段:执行 socket 的 close 事件回调
从上面可以看出,值得注意的阶段是 timer、poll和 check三个阶段。
timer阶段会执行 setTImeout 和 setInterval 的回调,并且这由 poll 阶段所控制的。但区别于浏览器,这里的定时器所指定的时间并不精确,它只能是尽快执行。 简单理解:在浏览器中的定时器是不同的宏任务,会按照创建顺序依次执行,而 Node 是尽快执行。poll阶段,会做很多事:- 回到
timer阶段,执行 timer 的回调; - 执行
I/O的回调。
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
- 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
- 回到
check阶段,setImmediate()的回调会被加入 check 队列中,从 event loop 的阶段图可以知道,check 阶段的执行顺序在 poll 阶段之后。
与浏览器的宏任务微任务共用一个队列结构不同的地方在于,现在的异步宏任务分成了多个阶段,每个阶段都对应着一个事件队列!
每当 Event Loop 执行当某个阶段时,便会执行对应的事件队列中的事件,并以此执行。
当该阶段的事件队列执行完毕,才会进入下一个阶段。
需要注意的是,
Event Loop每次切换一个事件执行队列时,便会查看微任务的队列,然后再切换到下一个队列中去。可以想象成,浏览器中,只有一个宏任务队列,每次新加的宏任务,会依次执行;而在 Node 中有多个宏任务队列,需要轮询进行执行。
知道了不同阶段有对应着不同的事件队列,就能理解 process.nextTick 了,它是在切换不同事件阶段的时候进行执行,并且这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 微任务 执行。这不同于setImmediate,setImmediate 只在 check 阶段执行,即 Event Loop 循环一次后,才执行一次。
setTimeout(() => {
console.log('timer1') // 1
Promise.resolve().then(function () {
console.log('promise1') // 6
})
process.nextTick(() => {
console.log('nextTick') // 2
process.nextTick(() => {
console.log('nextTick') // 3
process.nextTick(() => {
console.log('nextTick') // 4
process.nextTick(() => {
console.log('nextTick') // 5
})
})
})
})
}, 0)
// 打印: timer1 => nextTick => nextTick => nextTick => nextTick => promise1
先看一个简单的事件循环:
console.log('start') // 1
setTimeout(() => {
console.log('timer1') // 4
Promise.resolve().then(function () {
console.log('promise1') // 5
})
}, 0)
setTimeout(() => {
console.log('timer2') // 6
Promise.resolve().then(function () {
console.log('promise2') // 7
})
}, 0)
Promise.resolve().then(function () {
console.log('promise3') // 3
})
console.log('end') // 2
// start => end => promise3 => timer1 => timer2 => promise1 => promise2
思路非常清晰:
- 先执行全体宏任务,打印“start、end”,期间对
timer事件队列插入俩个 setTImeout 宏任务,再在当前宏任务中插入一个Promise.resolve.then()微任务; - 切换事件队列,但是当前微任务存在事件,因此执行微任务,打印“promise3”;
- Event Loop 轮询,到 timer 阶段,事件队列中存在俩个 setTImeout 事件,依次执行。打印“timer1”,插入
Promise.resolve.then()微任务; - 执行微任务队列,打印“promise1”。
- 执行宏任务,打印“timer2”,插入微任务。执行微任务,打印“timer2”。轮询完毕。
再看一个完整的事件循环:
setImmediate(() => {
console.log('setImmediate1')
setTimeout(() => {
console.log('setTimeout1')
}, 0)
})
setTimeout(() => {
console.log('setTimeout2')
Promise.resolve().then(function () {
console.log('promise1')
})
process.nextTick(() => {
console.log('nextTick1')
})
setImmediate(() => {
console.log('setImmediate2')
})
}, 0)
// 情况 1: setImmediate1 => setTimeout2 => nextTick1 => promise1 => setImmediate2 => setTimeout1
// 情况 2: setImmediate1 => setTimeout2 => nextTick1 => promise1 => setTimeout1 => setImmediate2
此时有俩种情况,我们来理一下思路: 需要说明的俩点是:1. 像setTimeout(() => {}, 0)这样的,虽然设置的等待时间是 0,但实际上执行还是会有 4ms 的延迟;2. 在 Node11 后,每个阶段的每个宏任务执行完毕后,都会去执行所有微任务。知道这两点,就能理解上述的代码了。
- 首先执行整体宏任务,此代码中没有别的任务,便给 check 事件队列插入
setImmediate1,同时setTimeout2这个异步事件开始执行,产生事件等待。此时还没有打印,而后进行 Event Loop 轮询; - 进入到 check 阶段,事件队列有任务,执行打印“setImmediate1”。执行异步函数
setTimeout1,产生新的事件等待。可以理解为此时 timer 事件队列为【setTimeout2,setTimeout1】。 - check 阶段执行完毕,查看微任务队列,没有微任务,进入到 timer 阶段。
- 进入到 timer 阶段,由于事件队列先后顺序的问题,此时应 setTImeout2 先执行(等待时间相同,先插入队列)。打印“setTimeout2”;给微任务队列插入“promise1”;给
nextTick事件队列插入nextTick1;给 check 事件插入 setImmediate2 事件; - 此时,宏任务
setTImeout2执行完毕,开始执行微任务。此时 nextTick 事件队列有任务,因此先执行,打印“nextTick1”;再看微任务队列,有任务内容,打印“promise1”; - 微任务执行完毕,此时较为关键,也是产生俩种结果的原因:
- 情况 1:timer 事件队列中的
setTimeout1已经执行等待完毕,继续执行宏任务 setTimeout1,打印setTimeout1。而后轮询到新的 check 阶段,执行 setImmediate2,打印“setImmediate2”。 - 情况 2:timer 事件队列中的
setTimeout1还在等待阶段,轮询到新的 check 阶段,执行 setImmediate2,打印“setImmediate2”;而后,再轮询到新的 timer 阶段,执行宏任务 setTimeout1,打印setTimeout1。
- 情况 1:timer 事件队列中的