令人困惑的闭包
令人困惑的闭包
终于来到闭包了,闭包其实挺难的。不信,你看下面的代码:
const foo = (function () {
var item = 0
return () => {
return item++
}
})()
for (let index = 0; index < 10; index++) {
foo()
}
console.log(foo())
上面的代码输出,答案是 10。没错,情理之中,意料之外。
我们来拆分一下,对于最后要输出的结果,先不考虑。对于立即执行函数 foo,我们先打印一下。
console.log(foo)
// 结果如下:
;() => {
return item++
}
node 环境中,可能会打印出 [Function (anonymous)] 。
因此,在循环执行 foo 时,会连续调用 相同的自由变量 item 10 次。最后一次 console.log(foo()) 时,得到 10。
这里的自由变量是指没有在相关函数作用域中声明,但却被使用了的变量。
没反应过来,也没有关系。我们再来回顾一下,这些相关知识就好了。
1 前置基础知识
1.1 作用域
在 JS 中,ES6 之前有 函数作用域 和 全局作用域 的区别。
简单的讲,就是 函数 { } 包裹起来的,可自成一块 函数作用域;其它的,就是直接暴露在外部的 全局作用域了。
var a = 'a'
var b = 'b'
function foo() {
a = 'fooA'
console.log(a) // 函数作用域内的 fooA
console.log(b) // 全局作用域内的 b
}
foo()
console.log(a) // 全局作用域下的 a 已被改变 fooA
在 JS 中,执行某个函数,如果遇到变量,就会优先在函数内部的作用于进行查找该变量(变量声明和变量提升,我们先按下不表)。如果,在函数体内部查找不到这个变量,那么我们就跳出这个函数作用域,到更上层作用域中查找。
1.2 块级作用域和暂时性死区
在上面的代码中,我们可以看到在函数体内部,我们可以直接修改全局变量,这个是我们不想看到的。因此 ES6 中,新增了 let 和 const 声明变量的块级作用域。
咋一看,可能感觉不出来这个好处。咱看一个小案例:
var i = 955
for (var i = 0; i < 10; i++) {
console.log('i:', i)
}
console.log('还能 955 吗?', i) // 10
看到了吧,连简单的 for 循环,都要考虑里面的变量有没有和全局作用域“相冲突”。块级作用域就解决了这个问题:
let i = 955
for (let i = 0; i < 10; i++) {
console.log('i:', i)
}
console.log('还能 955 吗?', i) // 955
问题解决了,我们来看看为什么会这样。
先来看看一个概念——“暂时性死区(Temporal Dead Zone)” 。(什么东西啊喂 Σ(゚ д ゚ lll) )
function foo() {
console.log(bar) // undefined
var bar = 955
}
foo()
你看,它竟然没有报错。其实,这段代码相当于:
function foo() {
var bar
console.log(bar) // undefined
bar = 955
}
foo()
就是,在用 var 定义一个变量时,它会在当前作用域下,发生 “变量提升” 的想象: 在作用域头部预先定义该变量,而后,在实际的位置进行变量赋值。
但是 let 和 const 的块级作用域呢?并不会发生这种想象:
function foo() {
console.log(bar) // ReferenceError: Cannot access 'bar' before initialization
let bar = 955
}
foo()
报错了,报错信息是,bar 没有初始化。这是因为 使用 let 或者 const 声明变了时,会正对这个变量形成一个封闭的块级作用域,在这个块级作用域中,若在声明变量前访问该变量,就会发生 ReferenceError 报错提示。因此,只能先定义该变量,而后再去访问。
我们再把这个代码改造一下,我们在全局作用域下先定义一个 bar 变量呢?可以正常输出吗?答案是不能。
var bar = 996
function foo() {
console.log(bar) // ReferenceError: Cannot access 'bar' before initialization
let bar = 955
}
foo()
为什么呢?这是因为 在相应的函数作用域内(foo 函数的花括号内)存在一个 “死区”,**起始于函数开头,终止于相关变量声明语句的所在行。**在这个范围内,无法访问使用 let 或者 const 声明的变量。
简单来讲,就是在用 let 或者 const 定义的变量,在当前的 作用域下,在它们声明语句的所在行 之前,我们无法调用这个定义的变量。
好了,明白这个之后,我们再来看一个代码:
function foo(arg) {
let arg // SyntaxError: Identifier 'arg' has already been declared
}
foo(arg)
这里涉及到了 接下来要说的 执行上下文/作用域 的知识了。上面的代码实际上等同于:
function foo(arg) {
var arg
let arg
}
1.3 执行上下文/作用域
首先说概念:
执行上下文就是当前代码的执行环境/作用域。附上一张执行上下文的生命周期图:
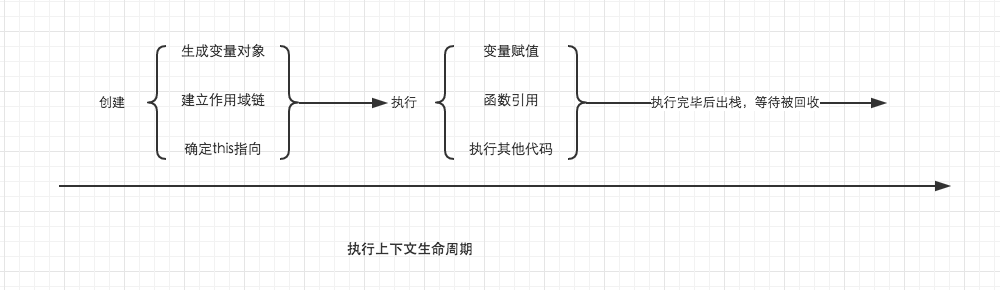
就是说,当我们调用一个函数时,会创建一个 新的执行上下文。而这个执行上下文,一共分为俩个阶段:
- 代码预编译阶段
- 代码执行阶段
注意,这里的预编译和 Java 等高级语音的预编译还不一样。(通俗解释:JavaScript 是解释性语言,编译一行,执行一行)
在预编译阶段,会做三件事:
- 创建变量对象;
- 建立作用域链;
- 确定 this 指向。
创建变量对象在这个过程中,有些重要的事情:
- 函数的所有形参
- 建立 参数对象
- 检查当前上下文参数,由名称和对应值组成的一个变量对象的属性被创建
- 没有实参,属性值设为
undefined
- 函数声明
- 检查当前上下文函数声明,也就是
function关键字声明的函数 - 在变量对象中,以函数名建立一个属性,属性值为指向该函数所在的内存地址的引用
- 若变量对象已经存在相同名称的属性,那该属性将会被新的引用所覆盖
- 检查当前上下文函数声明,也就是
- 变量声明
- 检查当前上下文中的变量声明
- 每找到一个变量声明,就在变量对象中以变量名建立一个属性,属性值为
undefined - 若变量名称相与已声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。(也就是防止同名属性被修改为
undefined,因此自动忽略,原属性值不会修改)
简单来讲,就是函数的创建过程中,顺序是: 参数定义 --> 函数定义 --> 变量声明定义
好了,我们看看执行过程会发生什么吧。
foo(955)
function foo(work) {
console.log(foo) // 1. undefined
foo = work
console.log(foo) // 2. 955
var foo
}
console.log(foo) // 3. [Function: foo]
foo = 996
console.log(foo) // 4. 996
我们来复盘一下整个过程:
首先在全局作用域下:
// 1. 没有参数,跳过 // 2. 函数声明: var foo 指向 [Function: foo] // 3. 变量声明 // foo 与函数名称相同, 跳过然后运行第一行代码
foo(955),在函数体内进行变量提升:// 1. 有参数, 进行赋值 var work = 955 // 2. 函数声明: 没有函数,跳过 // 变量声明: var foo而后,执行函数体内的实际代码:
console.log(foo) // 只是定义了, 还未赋值,并且因为存在, 所以不进行作用域链查找 // 输出 undefined foo = work // 赋值变量, 此时 foo 变为 955 了 console.log(foo) // 因此打印出来 955函数内部变量销毁,跳出函数体,继续执行外部代码:
console.log(foo) // 3. [Function: foo] 此时变量指向未变 foo = 996 // 这里, 函数被赋值了,指向发生变化 console.log(foo) // 4. 996
这整个过程很完整,我们来梳理一遍。
在预编译阶段,会创建变量对象(Variable Object, VO),此时只是把变量给创建了,还未赋值。等到了代码执行阶段,变量对象(Variable Object, VO)会被激活转换为(Active Object, AO),也就是传说中的 VO 先 AO 的转变。这个时候 作用域链也被确定了,它由当前执行环境的变量对象和所有外层已经完成的激活对象组成。这个步骤保障变量和函数的调用,如果在当前作用域中未找到,则会继续向上一层作用域进行查找,直至全局作用域。
1.4 调用栈
上面的梳理完了,调用栈就很好理解了。当调用一个函数的时候,这个函数又调用了其它函数,由此变形成了调用栈。
需要注意的地方是,当调用栈退出的时候,如果没有相关引用了,则相关的上下文会被销毁。
也就是垃圾回收机制,完整的标语应该是:
在函数执行完毕并退出栈时,函数内的局部变量在下一个垃圾回收(GC)节点会被回收,该函数对应的执行上下文将会被销毁,这也是我们无在外界无法访问函数内部定义的变量的原因。
也就是说,只有在函数执行的时候,相关的函数才可以访问该函数内部定义的变量。并且该变量会在预编译阶段被创建,在执行阶段被激活,最后在函数执行完毕后,其相关上下文会被销毁。
2 闭包
梳理完,上述知识点后,我们可以谈论闭包了。( 东西也太多了吧 (ಥ_ಥ) )
2.1 到底是什么?
闭包的定义有很多,我们这里就通俗的解释:
在函数嵌套函数时,内层函数引用了外层函数作用域下的变量,并且内存函数在全局环境下可以访问,进而形成闭包。
简单的讲,就是函数作用域内引用了外部作用域下的变量,这个时候就形成了闭包。
可能你会觉得,这个不是很正常嘛,通过作用域链调用嘛,没什么大不了的。我们把文章开头的代码进行一下改造:
function foo() {
let item = 0
return () => {
console.log(item) // 箭头函数引用 外部 item 变量
}
}
let getItem = foo()
getItem()
在这段代码中,foo 创建了一个变量 item ,并且返回了一个 箭头函数。而这个箭头函数中调用了这个变量 item,因此,在执行完 foo( ) 函数,相关的调用栈出栈之后,这个变量 item 并不会消失,而是仍然会被外界访问到。相当于它被封闭的结界包裹起来了,这就是闭包所产生的作用。
2.2 内存回收机制
这部分不属于闭包的知识了,但是了解后,可以有更深的体会。
几个相关的基础知识:
- 栈空间:由操作系统自动分配释放,存放函数参数值、局部变量值等,其操作方式类似于数据结构中的栈。
- 堆空间:由开发人员分配释放,这部分就属于对垃圾回收机制的运用了。
JS 中的数据类型:
基本数据类型,保存在栈空间中,由固定大小的内存空间。
undefined、null、number、string、boolean等引用数据类型,保存在堆空间中,内存空间大小不固定,需按引用情况来访问。
object、array和function等
由于 JavaScript 的回收机制,在函数调用完后,就会进行回收,为了保存特定变量,因此才有了闭包的出现。但是这也会造成隐患,如内存泄漏。我们看一个案例:
function foo() {
let work = 955
window.setInterval(function () {
console.log(work) // 调用外部变量, 形成闭包
}, 1000)
}
foo()
由于闭包的存在,work 的内存空间一直无法得到释放,最后造成内存泄漏。因此,需要在使用 cleanInterval 对其进行清理。
基本上就是这是这些知识点,其实其中还有很多可以掰碎了细说,但是不属于闭包的知识点了。所以就总结道这里吧。
谢谢你的时间。
以上。
参考资料
- JavaScript 高级程序设计
- JavaScript 深入之变量对象
- 前端开发核心知识进阶